
In this article, I will explain What Is The Formula For Standard Deviation. Standard deviation as a measure demonstrates how a set of data is distributed in relation to its average.
- What Is Standard Deviation?
- The Formula for Standard Deviation
- Step-by-Step Calculation Example
- Example Data:
- Step 1: Calculate the mean (xˉ\bar{x}xˉ)
- Step 2: Calculate the squared differences from the mean
- Step 3: Sum the squared differences
- Step 4: Divide by n−1n – 1n−1 (degrees of freedom)
- Step 5: Take the square root to find the standard deviation
- Why Is Standard Deviation Important?
- Pros And Cons
- FAQ
- Conclusion
Clarifying its formula helps with data variance analysis. This formula is important regardless of whether one is working with a population or a sample, and is foundational in data analysis and purposeful action.
What Is Standard Deviation?
The standard deviation essentially explains how much variation exists in a set of data points. A low standard deviation indicates that the values are clustered around the mean. In contrast, a higher standard deviation occurs when the value are more spread out from the mean.
This number summarizes data distribution and makes it more straightforward to compare two different data sets, or to make sense of one data set.
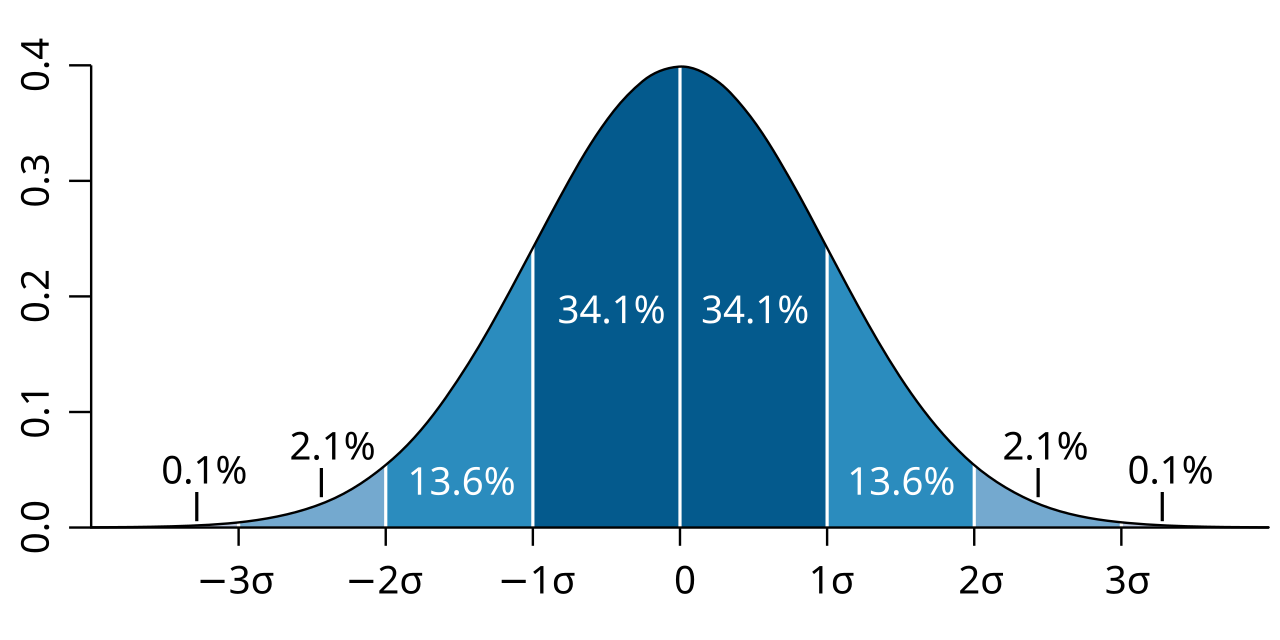
Let’s say you have the test scores of a class. The standard deviation will be able to tell you how congruent or incongruent the students’ scores were.
If the standard deviation is small, then it indicates that many students performed close to the mean score. But a high consistency in low or high scores would indicate a higher standard deviation.
The Formula for Standard Deviation
There are two main types of standard deviation formulas — one for a population and one for a sample. The difference lies in the denominator, reflecting whether you have data for the entire group or just a subset.
1. Population Standard Deviation Formula
If you have data for the entire population, the formula for standard deviation (denoted as σ, the Greek letter sigma) is: σ=∑(xi−μ)2N\sigma = \sqrt{ \frac{ \sum (x_i – \mu)^2 }{ N } }σ=N∑(xi−μ)2
Where:
- σ\sigmaσ = population standard deviation
- xix_ixi = each individual data point
- μ\muμ = population mean (average of all data points)
- NNN = total number of data points in the population
- ∑\sum∑ = the sum of all the values that follow
2. Sample Standard Deviation Formula
If you only have a sample (a subset of the population), you use a slightly adjusted formula to better estimate the population standard deviation. This is denoted as sss: s=∑(xi−xˉ)2n−1s = \sqrt{ \frac{ \sum (x_i – \bar{x})^2 }{ n – 1 } }s=n−1∑(xi−xˉ)2
Where:
- sss = sample standard deviation
- xix_ixi = each individual data point in the sample
- xˉ\bar{x}xˉ = sample mean (average of the sample data)
- nnn = number of data points in the sample
- n−1n – 1n−1 = degrees of freedom (used to correct bias in the estimate)
Step-by-Step Calculation Example
Let’s walk through an example to understand how to calculate the sample standard deviation.
Example Data:
Consider the sample data set: 4, 8, 6, 5, 3
Step 1: Calculate the mean (xˉ\bar{x}xˉ)
xˉ=4+8+6+5+35=265=5.2\bar{x} = \frac{4 + 8 + 6 + 5 + 3}{5} = \frac{26}{5} = 5.2xˉ=54+8+6+5+3=526=5.2
Step 2: Calculate the squared differences from the mean
| Data Point xix_ixi | xi−xˉx_i – \bar{x}xi−xˉ | (xi−xˉ)2(x_i – \bar{x})^2(xi−xˉ)2 |
|---|---|---|
| 4 | 4 – 5.2 = -1.2 | (-1.2)^2 = 1.44 |
| 8 | 8 – 5.2 = 2.8 | 2.8^2 = 7.84 |
| 6 | 6 – 5.2 = 0.8 | 0.8^2 = 0.64 |
| 5 | 5 – 5.2 = -0.2 | (-0.2)^2 = 0.04 |
| 3 | 3 – 5.2 = -2.2 | (-2.2)^2 = 4.84 |
Step 3: Sum the squared differences
1.44+7.84+0.64+0.04+4.84=14.81.44 + 7.84 + 0.64 + 0.04 + 4.84 = 14.81.44+7.84+0.64+0.04+4.84=14.8
Step 4: Divide by n−1n – 1n−1 (degrees of freedom)
14.85−1=14.84=3.7\frac{14.8}{5 – 1} = \frac{14.8}{4} = 3.75−114.8=414.8=3.7
Step 5: Take the square root to find the standard deviation
s=3.7≈1.92s = \sqrt{3.7} \approx 1.92s=3.7≈1.92
So, the sample standard deviation is approximately 1.92.
Why Is Standard Deviation Important?
Standard deviation finds its applications in diverse fields such as finance, engineering, psychology, and social sciences. It is effective in:
Evaluate Reliability of Data: In comparison, a smaller standard deviation indicates that the data points are reliable as they lie in close proximity to the average.
Risk Evaluation: In finance, it determines the volatility of stock price or return.
Quality Inspection: In manufacturing, it evaluates the consistency of products.
Statistical Generalization: It supports creating highly accurate predictions.
Pros And Cons
| Pros | Cons |
|---|---|
| Measures Data Spread Clearly: Shows how much data varies around the mean. | Can Be Affected by Outliers: Extreme values can inflate the standard deviation. |
| Widely Used and Understood: A standard metric in statistics and many fields. | Requires Calculation: More complex than simple measures like range or mean. |
| Helps in Risk Assessment: Important in finance, quality control, and research. | Interpretation Can Be Tricky: Requires some statistical knowledge to interpret correctly. |
| Works for Both Population and Samples: Two formulas adjust for data type. | Only Measures Spread: Doesn’t show data distribution shape (e.g., skewness). |
| Provides Basis for Other Stats: Key for variance, confidence intervals, and hypothesis testing. | Sensitive to Data Scale: Different units or scales affect its value and comparison. |
FAQ
Can standard deviation be negative?
Is there a difference between variance and standard deviation?
Conclusion
To summarize, the standard deviation measures data dispersion in relation to the mean which evaluates variation and consistency.
Populations and samples have different formulas, but both require determining the mean squared deviation and the square root is computed afterwards. This formula operates in a wide variety of fields, hence understanding data calculation is critical.









